
At Microsoft, we invest a lot of time researching and investigating possibilities in our journey to memory safety. Because the massive majority of existing codebases are written in unsafe programming languages, the task of protecting legacy code is very important.
Hardware solutions are an attractive approach because they introduce very powerful security properties with low overheads compared to purely software solutions. There is a lot of research published on MTE and CHERI, which we encourage you to check out. There is a great overview and a lot of references to publication by different parties in the blogpost “Survey of security mitigations and architectures, December 2022”.
The IoT and embedded ecosystems introduce some unique challenges. Unfortunately, these ecosystems are built upon a diverse set of codebases written in C/C++ (mostly C), usually with zero mitigations in place, due to real or perceived overheads. This means that there are a lot of memory safety vulnerabilities that are easily exploited. In addition, existing hardware often provides no isolation at all. When it does, it’s often limited to 2-4 privilege levels and a small number of isolated memory regions, not something that can scale to object-granularity memory safety.
In November 2022, we (MSR, MSRC and Azure Silicon) published a blogpost about our new project for these spaces – “What’s the smallest variety of CHERI?”. The idea is to build a CHERI-based microcontroller that aims to explore whether/how we can get very strong security guarantees if we are willing to co-design the instruction set architecture (ISA), the application binary interface (ABI), isolation model, and the core parts of the software stack. The results are outstanding, and in our blogpost we detail how our microcontroller achieves the following security properties:
- Deterministic mitigation for spatial safety (using CHERI-ISA capabilities).
- Deterministic mitigation for heap and cross-compartment stack temporal safety (using a load barrier, zeroing, revocation, and a one-bit information flow control scheme).
- Fine-grained compartmentalization (using additional CHERI-ISA features and a tiny monitor).
In early February 2023 we open sourced the hardware and software stack on GitHub, along with our tech report - CHERIoT: Rethinking security for low-cost embedded systems. This release includes an executable formal specification of the ISA, a reference implementation of that ISA built on the Ibex core from lowRISC, a port of the LLVM toolchain, and a clean-slate privilege-separated embedded operating system.
This blogpost aims to make this platform accessible for security researchers to get their hands dirty with our project, have a working setup and experiment with it directly. We encourage everyone to find bugs, contribute and be part of this effort.
Getting started with CHERIoT
The Getting Started Guide provides an overview of how to build and install all of the dependencies. You can skip most of these steps if you use the dev container we provide, either using local Visual Studio Code or GitHub Codespaces.
Using GitHub Codespaces is very simple, straightforward, and fast. Simply create a new Codespace, choose the microsoft/cheriot-rtos repository, and you are done. You’ll get an IDE in your browser with all dependencies preinstalled. From now on, whenever you want to use Codespaces for the project, simply open your Codespaces, and you can launch them from there.
This will let you navigate the code, with syntax highlighting and autocompletion configured to work with the CHERIoT language extensions, and provides a terminal for building the components and running in the simulator generated from the formal model of the ISA.
To run the examples, simply enter the directory for each one, run xmake to build it, and then pass the resulting firmware image to /cheriot-tools/bin/cheriot_sim:
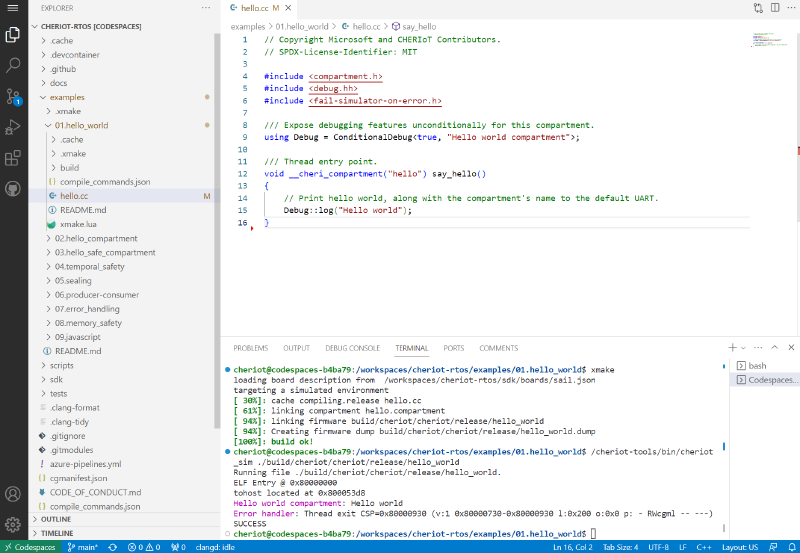
The cheriot_sim tool supports instruction-level tracing. If you pass -v, it will print every instruction that’s executed, letting you see exactly what’s happening in your code.
Of course, you can also work locally in your preferred environment. We provide a dev container image that has the dependencies preinstalled. VS Code and other editors that support the Development Containers specification should use it automatically. You can also build the dependencies yourself. If our instructions don’t work for your preferred environment, please file an issue or raise a PR.
Threat model
We provide strong guarantees between compartments and some additional defense in depth that makes compromising individual compartments difficult. We will discuss these separately.
Intracompartment
In our blog “What’s the smallest variety of CHERI?” we presented the low level details for all the memory safety properties the compiler and the runtime environment can use CHERI to enforce:
- Stack spatial safety.
- Spatial safety for objects with static storage duration.
- Spatial safety for pointers passed into the compartment.
- Temporal safety for pointers passed into the compartment.
- Heap spatial safety.
- Heap temporal safety.
- Pointer integrity (it’s not possible to fake or corrupt pointers).
The compiler is responsible for enforcing the first two of these properties. This means that assembly code can violate these two properties but not any of the others.
This gives us the ability to enforce very powerful memory safety on legacy C/C++ (and buggy-but-not-actively-malicious assembly) code within the compartment. For example: everything in the network stack, media parsers, and so on that deal with untrusted input and object management get automatic bounds checking and lifetime enforcement with zero source modifications.
Any instruction that would break our security rules is guaranteed to trap and so it cannot cause any damage. This is why the mitigations we get are deterministic.
Intercompartment
Each compartment is an isolated, separate security context. No compartment should be able to break the object model built by another compartment. We assume arbitrary code execution inside the compartment – i.e., an attacker could have their own compartment with their own code, and we want to enforce the following security properties on the system:
- Integrity: An attacker cannot modify another compartment’s state unless explicitly permitted to do so.
- Confidentiality: An attacker cannot see another compartment’s data unless it is explicitly shared.
- Availability: An attacker cannot prevent another thread of equal or higher priority from making progress.
In general, integrity is the most important of these, because an attacker who can violate integrity can modify code or data to leak data or prevent forward progress. Confidentiality is the next most important. Even a simple IoT device such as an Internet-enabled lightbulb may, by leaking its one bit of internal state, give an attacker information about whether a house is occupied and so confidentiality is the next most important.
The importance of availability is situational. For safety-critical devices, it can be more important than either of the other two properties (most people fitted with a pacemaker would rather that an attacker can corrupt their medical records than remotely trigger a heart attack, for example). For others, if a device (or a service on the device) crashes and needs to reset then that’s a minor inconvenience, especially when the boot time is tiny fractions of a second.
In the current version, our threat model encompasses confidentiality and integrity, but work on availability is still ongoing. For example, we have a mechanism that allows compartments to detect and recover from faults but it’s not yet used everywhere. Therefore, any bug that violates confidentiality or integrity is treated as critical, anything that violates availability needs to be fixed before anyone can consider using the platform for safety-critical tasks.
Mutual distrust
Our system is built on the principle of mutual distrust. In the case of some core components, this is somewhat striking. For example, users of the memory allocator trust it not to hand out the same memory to different callers, but the allocator retains access to all of heap memory; however, calling the memory allocator does not grant it access to any of your compartment’s non-heap memory. Similarly, the scheduler time-slices the core between a collection of threads but is not trusted for confidentiality or integrity by any of these threads as it holds for each only an opaque handle, which cannot be dereferenced, allowing it to choose which one runs next but not access associated state. In contrast, most operating systems are built on a ring model of hierarchical distrust, where a hypervisor can see all state owned by guest VMs, guest kernels can see all state owned by processes that they run.
In our mutual-distrust model, gaining complete control requires that you compromise multiple compartments. Compromising the scheduler, for example, does not give you access to all threads, but it does give you the ability to try to attack threads that depend on scheduler services for things like locking. Compromising the memory allocator lets you violate heap memory safety and attack compartments that depend on the heap.
Examples
To see how some of the guarantees are achieved, let’s try removing some of the checks and see what exploitation primitives we get.
Example #1 – (Try) attacking the scheduler
For example, let’s remove a check in a code path called by the scheduler and explore the interesting reasons that system availability is unaffected. As we wrote in our blogpost:
“Note that the sealing operation means that the scheduler does not have access to a thread’s register state. The scheduler can tell the switcher which thread to run next, but it cannot violate compartment or thread isolation. It is in the TCB for availability (it can refuse to run any threads) but not for confidentiality or integrity.”
This design means the scheduler is out of the TCB for integrity and confidentiality, which means that any potential bugs there affect availability, and only availability.
In addition, please note the scheduler does not have an error handler installed. That’s because, without an error handler, the switcher will force unwind to the calling compartment. This eliminates most of the potential DoS attacks on the scheduler, because it will always force unwind to the caller, without affecting the availability, integrity or confidentiality of the system. The scheduler is written to ensure that its state is always consistent before dereferencing a user-provided pointer that may induce a trap.
The check we are going to remove is an important one. Take a look at the code in heap_allocate_array sdk/core/allocator/main.cc:
[[cheri::interrupt_state(disabled)]] void *
heap_allocate_array(size_t nElements, size_t elemSize, Timeout *timeout)
{
...
if (__builtin_mul_overflow(nElements, elemSize, &req))
{
return nullptr;
}
...
}
As you can see, we have a check for integer overflow on the size of the allocation. Because we are using pure-capability CHERI, even without this check, it’s not possible to access the allocation beyond its bounds. That’s because whatever size the heap will allocate, the exact bounds are still set in the capability. We will simply trigger a CHERI exception on the very first load/store that will go out-of-bounds (yes, CHERI is fun!).
Let’s see that happen in practice. We will remove the integer overflow check and trigger a call to heap_allocate_array with arguments that overflow and trigger a small allocation (when the caller intends for a much, much bigger one). Normally, such scenarios result in wild copies. But again, with CHERI-ISA, the processor won’t let that happen.
The scheduler (sdk/core/scheduler/main.cc) exposes Queue APIs. One of them is queue_create, which calls calloc with our controlled arguments. And in turn, calloc calls heap_allocate_array. You can look at the producer-consumer example in the project, to see how you can use this API. It’s very simple.
For our example, we made the following changes to trigger the bug from the queue-test under tests:
Change the value passed as itemSize in tests/queue-test.cc:
- int rv = queue_create(&queue, ItemSize, MaxItems);
+ int rv = queue_create(&queue, 0x80000001, MaxItems);
Remove the integer overflow check in sdk/core/allocator/main.cc:
- size_t req;
- if (__builtin_mul_overflow(nElements, elemSize, &req))
- {
- return nullptr;
- }
+ size_t req = nElements * elemSize;
+
+ //if (__builtin_mul_overflow(nElements, elemSize, &req))
+ //{
+ // return nullptr;
+ //}
In sdk/core/scheduler/main.cc (both in queue_recv and queue_send):
- return std::pair{-EINVAL, false};
+ //return std::pair{-EINVAL, false};
And, just for debugging purposes, add the following debug trace in sdk/core/scheduler/queue.h, in the send function, right before the memcpy:
+ Debug::log("send(): calling memcpy with ItemSize == {}", ItemSize);
memcpy(storage.get(), src, ItemSize); // NOLINT
This will allocate a storage of size 2, and fault in the memcpy. Then, we will force unwind to the calling compartment and fail, as you can see here:

We forced unwind from the scheduler to the queue_test compartment, and we see the failure in the return value of queue_send. The scheduler keeps running, and the system’s availability is unaffected.
Example #2 - Breaking Integrity and Confidentiality
As we wrote in our blogpost, the most privileged component is the switcher:
“This is responsible for all domain transitions. It forms part of the trusted computing base (TCB) because it is responsible for enforcing some of the key guarantees that normal compartments depend on. It is privileged because its program counter capability grants it explicit access to the trusted stack register, a special capability register (SCR) that stores the capability used to point to a small stack used for tracking cross-compartment calls on each thread. The trusted stack also contains a pointer to the thread’s register save area. On context switch (either via interrupt or by explicitly yielding) the switcher is responsible for saving the register state and then passing a sealed capability to the thread state to the scheduler.
The switcher has no state other than the state borrowed from the running thread via the trusted stack and is small enough to be audited easily. It always runs with interrupts disabled and so is simple to audit for security. This is critical because it could violate compartment isolation by not properly clearing state on compartment transition and could violate thread isolation by not sealing the pointer to the thread state before passing it to the scheduler.”
The switcher is the only component that both deals with untrusted data and runs with the access-system-registers permission. It is slightly more than ~300 RISC-V instructions, which means our TCB is very small.
So, for example, let’s remove one check in the switcher and see how it introduces a vulnerability that affects everything - availability, integrity, and confidentiality.
In the switcher, in the beginning of compartment_switcher_entry, we have the following check:
// make sure the trusted stack is still in bounds
clhu tp, TrustedStack_offset_frameoffset(ct2)
cgetlen t2, ct2
bgeu tp, t2, .Lout_of_trusted_stack
This code makes sure the trusted stack is not exhausted and we have enough space to operate on. If not, we jump to a label called out_of_trusted_stack, which triggers a force unwind, which is the correct behavior in such a case. Let’s see what will happen if we remove this check and try to exhaust the trusted stack.
The first question to ask is “how would one exhaust the trusted stack?”. This happens to be pretty simple – if we want to use more and more of trusted stack memory, all we need is to keep calling functions cross-compartment, without returning. The test we added in tests/stack_exhaustion_trusted.cc does exactly that:
- We define a
__cheri_callback(a safe cross-compartment function pointer) in thestack-testcompartment, which calls the entry point of another compartment. Let’s call that compartmentstack_exhaustion_trusted. - The entry point of
stack_exhaustion_trustedgets a function pointer and calls it. - Since the function pointer points to code in
stack-test, the call triggers a cross-compartment call to thestack-testcompartment, which calls again the entry point ofstack_exhaustion_trustedcompartment, and this keeps running in an infinite recursion until the trusted stack is exhausted.
By doing so, the switcher faults and we hit the fault-handling path, which either unwinds or calls an error handler in the faulting compartment. The problem here is that the fault happens in the switcher but is treated as if it happened in the calling compartment. When the switcher invokes the compartment’s error handler, it passes a copy of the register state at the point of the fault. This register dump includes some capabilities that should never be leaked outside of the switcher.
Our malicious compartment can install an error handler, catch the exception, and get registers with valid switcher capabilities! In particular, the ct2 register holds a capability to the trusted stack for the current thread, which includes unsealed capabilities to any caller’s code and globals, along with stack capabilities for the ranges of the stack given by other capabilities. Worse, this capability is global and so the faulting compartment may store it in a global or on the heap and then break thread isolation by accessing it from another thread.
The following functions get an ErrorState *frame (the context of the registers the error handler gets) and detect switcher capabilities:
using namespace CHERI;
bool is_switcher_capability(void *reg)
{
static constexpr PermissionSet InvalidPermissions{Permission::StoreLocal,
Permission::Global};
if (InvalidPermissions.can_derive_from(Capability{reg}.permissions()))
{
return true;
}
return false;
}
bool holds_switcher_capability(ErrorState *frame)
{
for (auto reg : frame->registers)
{
if (is_switcher_capability(reg))
{
return true;
}
}
return false;
}
Great, we have an easy way to detect switcher capabilities. If we have a valid capability to the switcher compartment, we can own the system and break integrity and confidentiality (and availability, but that’s given).
Now we need to implement the logic that will exhaust the trusted stack in the switcher and make sure we have an exception handler that checks for switcher capabilities in the register context.
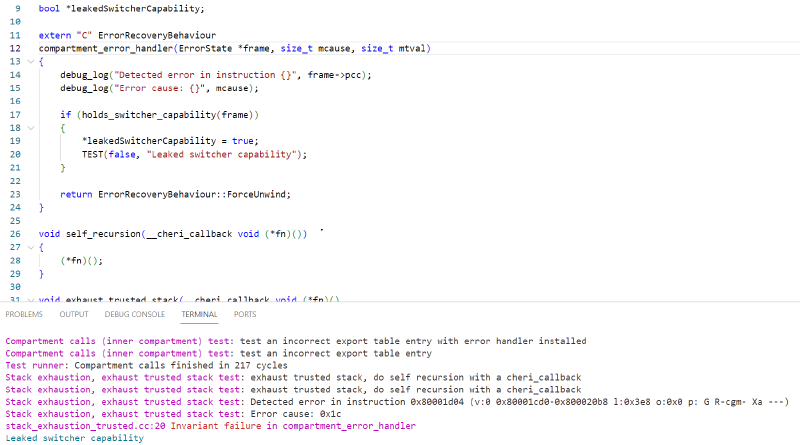
This is exactly what we do in stack_exhaustion_trusted.cc. The code couldn’t be simpler:
bool *leakedSwitcherCapability;
extern "C" ErrorRecoveryBehaviour
compartment_error_handler(ErrorState *frame, size_t mcause, size_t mtval)
{
debug_log("Detected error in instruction {}", frame->pcc);
debug_log("Error cause: {}", mcause);
if (holds_switcher_capability(frame))
{
*leakedSwitcherCapability = true;
TEST(false, "Leaked switcher capability");
}
return ErrorRecoveryBehaviour::ForceUnwind;
}
void self_recursion(__cheri_callback void (*fn)())
{
(*fn)();
}
void exhaust_trusted_stack(__cheri_callback void (*fn)(),
bool *outLeakedSwitcherCapability)
{
debug_log("exhaust trusted stack, do self recursion with a cheri_callback");
leakedSwitcherCapability = outLeakedSwitcherCapability;
self_recursion(fn);
}
And, in stack-test.cc, we define our __cheri_callback as:
__cheri_callback void test_trusted_stack_exhaustion()
{
exhaust_trusted_stack(&test_trusted_stack_exhaustion,
&leakedSwitcherCapability);
}
Let’s execute it! All we need to do is to build the test-suite, by running xmake in the tests directory. And then:
/cheriot-tools/bin/cheriot_sim ./build/cheriot/cheriot/release/test-suite
Sum up
As you can see, scaling CHERI down to small cores is a life-changing step to the IoT and embedded ecosystems. We encourage you to contribute to the project on GitHub and be part of these efforts!
References:
Thanks,
Saar Amar – Microsoft Security Response Center
David Chisnall, Hongyan Xia, Wes Filardo, Robert Norton – Azure Research
Yucong Tao, Kunyan Liu – Azure Silicon Engineering & Solutions
Tony Chen – Azure Edge & Platform